
As there are various problems to be solved by machine learning, there are various types of machine learning.
In the past, machine learning algorithms were largely divided into supervised learning and unsupervised learning. Recently, as reinforcement learning becomes more important, it is being divided into supervised learning, unsupervised learning, and reinforced learning.
Supervised learning
In supervised learning, data is given as input (feature vector) and output (target value) pairs. For the input feature vector, we use the name ‘supervised’ in the sense that it tells us what the output should be.
Problems that can be solved by supervised learning include regression and classification. Regression is given as a series of real numbers, but classification is given in several classes.
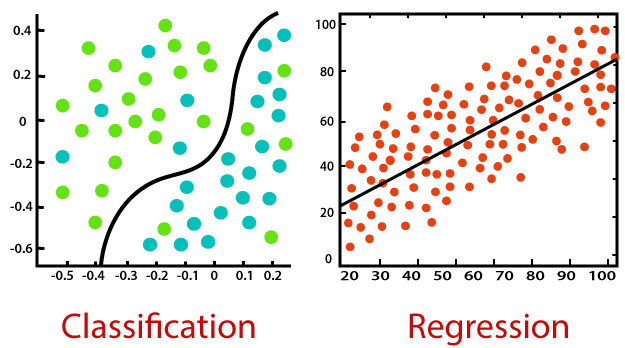
Recent advances in machine learning have led to an increasing number of cases where supervised learning solves new forms of problems other than regression and classification. The ranking is mainly used in a search. The purpose of the ranking is to find related documents and rank them according to the relevance to provide the users.
Another application problem is image conversion. For example, if you enter a picture and a famous artist at the same time, program converts the picture into the style of a famous artist. As deep learning becomes more common, machine learning is being applied to a wide range of previously unimagined problems to expand its scope of application.
Unsupervised learning
In unsupervised learning, only inputs (feature vectors) are given. Since only the feature vector is given and there is no target value, it is called unsupervised learning in the sense of not teaching. For example, we use unsupervised learning when we want to categorize mail, and we want to categorize it according to propensity without telling us what kind of mail it should classify, such as spam or work-related mail.
Then, in the absence of classification information, the most basic thing a computer can do is think of clustering. Clustering is the process of gathering samples that are close together in a feature space into the same cluster. For example, clustering is necessary in a situation where a personalized advertisement is targeted to customers in an online shopping mall. This is because clustering customer occupation, gender, age, and preferences can predict which advertisements should be shown.
Another thing to do in unsupervised learning is the transformation of feature space. If the dimension of the feature space increases and the size of the data base increases, it becomes difficult for a person to judge intuitively. In this case, unsupervised learning can be used to automatically find the transform function. All transformations occurring in the hidden layer of deep neural networks are called expression learning or feature learning.

Reinforcement learning
Reinforcement learning is a method of giving a goal value, and the shape of the goal value is very different from that of supervised learning. In the example of a chess game, two people take turns embroidering. We can sample each turn. Unlike supervised learning, which gives a target value for each sample, reinforcement learning gives the target score after the game is finished. It only gives one target value to a series of samples. Therefore, an additional algorithm is needed to distribute the target value to each sample in the sample row. AlphaGo is a popular example of using a strategy that blends supervised and reinforcement learning.


Semi-supervised learning
Collecting quasi-data is expensive. Gathering data corresponding to the inputs is relatively easy, but setting targets is expensive because humans must perform them. For example, if you want to analyze the number of customers in a store with CCTV, and you are constantly uploading images from CCTV to the database in real time, gathering inputs is easy. But to figure out how many people are moving back and forth in this video, you have to count them yourself. Semi-supervised learning assigns class information to only a small amount of data, and then seeks to improve performance by using a small amount of data with class information and a large amount of data without class information.
