
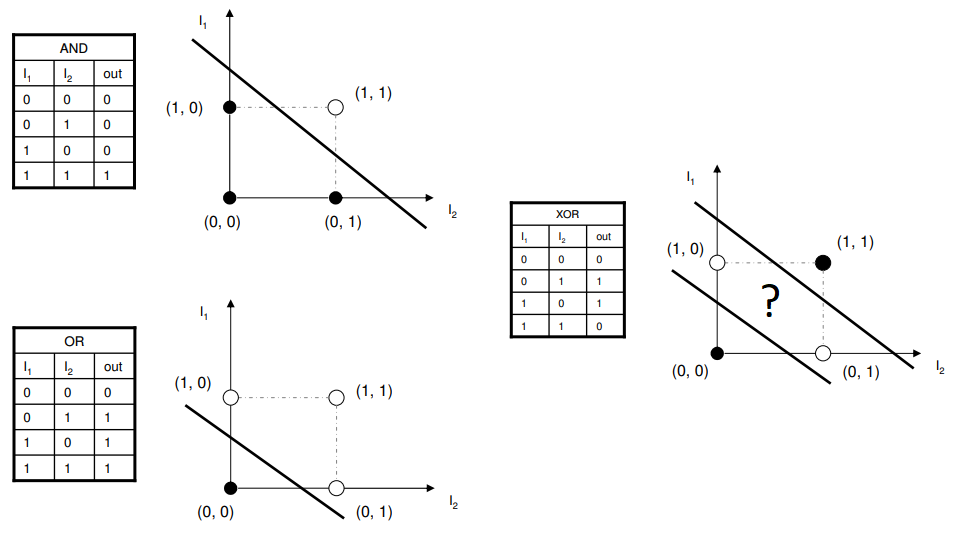
Perceptron has the limitation that it can only handle situations where linear separation is possible. The problem of XOR classification is that the perceptron has a 75% accuracy rate because one sample is wrong no matter which decision line is used.
In 1969, Marvin Minsky’s Perceptrons, the father of artificial intelligence, revealed this fact, and the 1970s became the dark age of neural network research. Marvin Minsky talked about overcoming Perceptron’s limitations, but computer technology was not realized at the time. In 1974, Wareboth proposed an error backpropagation algorithm in a doctoral dissertation, the core of which is a multilayer perceptron.
Multilayer perceptron solves the situation where linear separation is impossible by using a multi-layered structure combining several perceptrons. The new technique introduced by multilayer perceptron is as follows.
- Put a hidden layer.
- Introduce the sigmoid activity function.
- Use an error backpropagation algorithm.
Type of active function

In the learning process, a large number of function values and first derivatives are calculated, and this calculation determines the total learning time. Therefore, it is very important to calculate this function quickly. Since the logistic sigmoid’s first derivative includes the function itself, storing the value of the function can complete the derivative calculation with one subtraction and one multiplication.
Comparing the output of the perceptron using the step function and the perceptron using the logistic sigmoid, the step function forms a cliff at a right angle at the boundary, but the sigmoid has a gentle slope at the boundary.
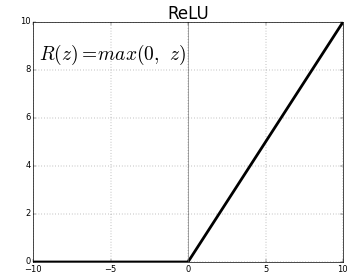
Historically, Perceptron used a step function and multilayered Persebronn used logistic sigmoid or hyperbolic tangent. The ReLU function was discovered late. If deep learning uses logistic or hyperbolic tangents, the problem is that the gradient disappears during learning, resulting in a gradient disappearance that eventually approaches zero. In this case, the problem is greatly alleviated by replacing the ReLU function. In addition, the ReLU function can be calculated in one comparison operation, which is very useful for speeding up deep learning. However, the problem arises because all negative numbers are replaced with zeros. Several variants have been developed to solve this problem.
Structure of Multi-Layer Perceptron

Looking at the structure of the multilayer perceptron, a hidden layer lies between the output layer and the two-wall layer. The input layer is where the inputs of a given feature vector are input and the output layer is where the final output of the neural network can be seen, while the hidden layer is named hidden, meaning that it is invisible as an intermediate process of computation. . Unlike perceptron, it is called multilayer perceptron (MLP) because it has multiple layers.