
The autoencoder is a neural network that receives the feature vector x and outputs the same or similar vector x ‘. The figure below shows the structure of an autoencoder. Since the output must be the same as the input, the number of nodes in the output layer and the number of nodes in the input layer are the same.
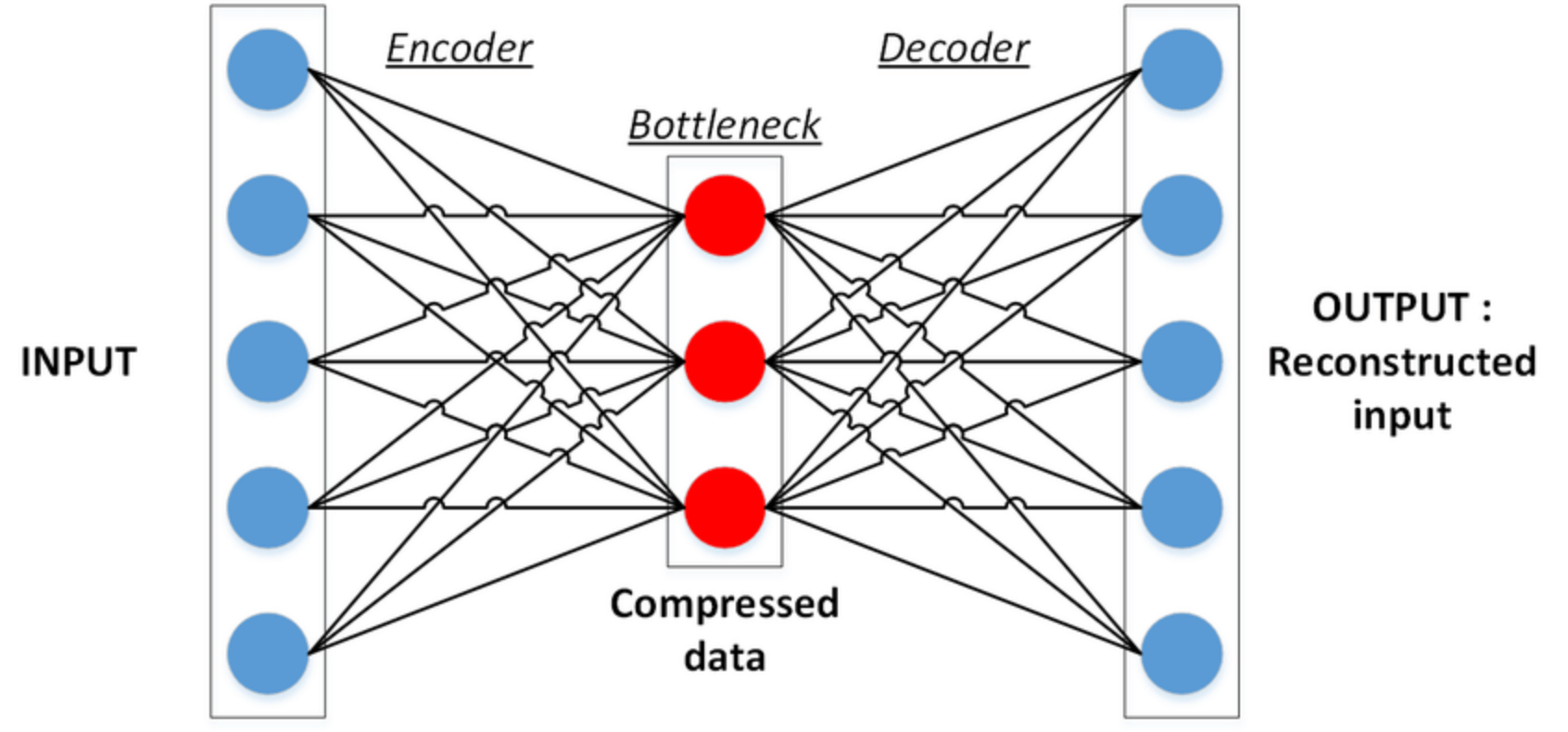
The autoencoder is unsupervised learning with no label information in the training set. However, given the condition that the input and output must be the same, the original training set X = {x1, x2, …, xn} is replaced by X = {x1, x2, …, xn}, Y = {x1, x2, …, xn} can be extended to do supervised learning. However, if the input and output need to be the same, you can easily implement it using an identity matrix. If you write it as an expression: In this equation, W and V representing the set of weights are the identity matrix I. This multiplying the identity matrix twice makes it useless.
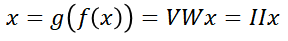
There are several regulatory techniques that are very effective in overcoming the limitations of this simple radiation. In addition, the autoencoder is suitable for stacking in multiple layers, and an efficient learning algorithm has been developed for a stacked autoencoder with a deep structure.
Principle of operation
When the number of nodes m of the hidden layer is smaller than the number of nodes d of the input layer, the auto encoder has a meaning. For example, if the size of the input image is large and the number of nodes in the hidden layer of the auto-encoder is smaller than the number of nodes in the input layer, much less memory can be stored. And you can always restore the original x through the decoder if you need to. The hidden layer h can be said to have extracted key information, that is, a very prominent feature.
In the early days, the bottleneck structured auto-encoder was manufactured and used mainly for dimension reduction. However, with the advent of sparse coding techniques, successful success has been achieved in an over-perfect way that uses far more elements than are actually needed.
Autoencoder can be designed differently according to the standard. According to the number of hidden nodes, m d can be divided into cases, and depending on the operation performed by the node can be divided into linear and non-linear.
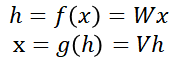
Consider the learning of an autoencoder. The data given is the training set X = {x1, x2, …, xn} and the parameters to find are the mapping functions f and g, the weights W and V. If we call the parameters W and V theta, we can use Otter Encoder learning as an optimization problem.
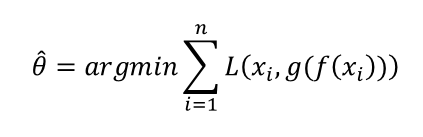
L is a loss function that acts as an objective function. Several loss functions are possible.
Stacked autoencoder

Shallow autoencoders have limitations, just as shallow MLPs have only one or two hidden layers. In the MLP, the autoencoder can be extended to a deep structure by stacking multiple hidden layers, as the hidden layer is expanded to extend the deep structure to increase capacity and improve performance. This expanded structure is called a stacked auto encoder.
I just want to say I’m very new to blogging and site-building and definitely enjoyed this web blog. Most likely I’m want to bookmark your website . You amazingly come with excellent articles and reviews. Thanks a bunch for sharing your blog.