
Today I want to learn how to crawl with python. Crawling is one of the ways to collect the data I want from outside. Usually, companies use internal data to analyze, but if they can’t, they have to collect the data themselves from the outside. This is the method used in that case.
- requests module
There is a requests module to handle http requests. It is made to conveniently use the urllib module built into Python. You can install it using pip.
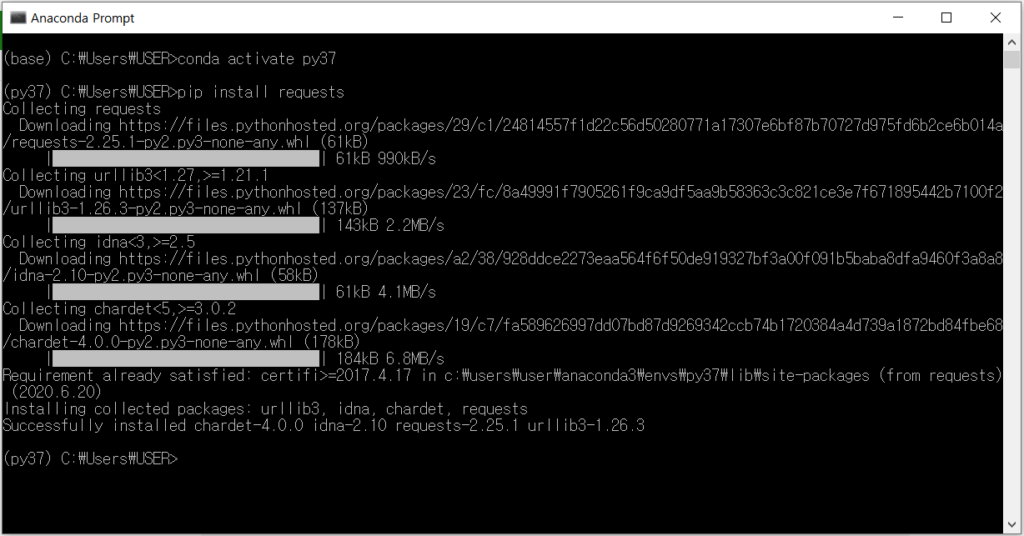
You can find out how to use it by accessing the requests module’s official homepage, https://pypi.org/project/requests/.
>>> import requests
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
'{"type":"User"...'
>>> r.json()
{'disk_usage': 368627, 'private_gists': 484, ...}
You can see if the request has been properly executed through status_code. If 200 is displayed, it is correct, and if a 3-digit number starting with 404 or 5 is displayed, it means bad request.

2. beautifulsoup
It is a Python library for extracting data. Let’s install this in advance using pip.
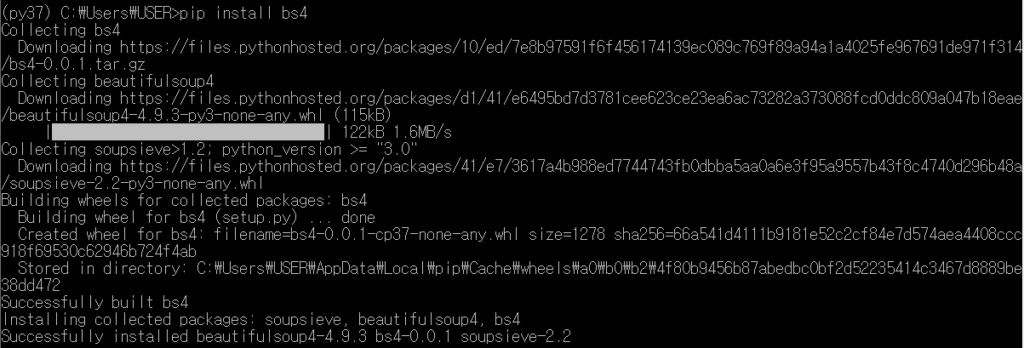
It is easy to use bs4.
from bs4 import BeautifulSoup URL = "url you want" html = get_html(URL) soup = BeautifulSoup(html, 'html.parser')
Now let’s start crawling. I will gather information on the Red Scale related papers that I am interested in on the Google Academic Search page.
def save_to_file(paper):
file = open("red_scale.csv", mode="w")
writer = csv.writer(file)
writer.writerow(['Name', 'Author', 'link'])
for paper in papers:
writer.writerow(list(paper.values()))
return