
It’s been a long time since I am back to the machine learning post. Let’s take a look at what I have been dealing with.
Supervised learning
Supervised learning is to train data using labeled data. Given an input value (X data), it learns the Label (Y data) for the input value and typically has classification and regression problems.
1) Classification
Classification refers to the problem of classifying given data according to a set category (label). There are binary classification problems such as correct or not for classification, or multiple classification problems such as appleda, banana, grape, etc.
2) Regression
Regression is a problem of predicting continuous values based on features of certain data, and is mainly used to predict certain patterns, trends, and trends. In other words, the answer is not just falling like 1 or 0 like a classification.
Decision Tree
Decision trees can be both classification and regression. That means you can predict both categorical and continuous numbers. More details can be found at the link Decistion Tree
Ensemble
We have used several machine learning algorithm techniques so far, but we often feel that there are limits to what can be achieved with only one algorithm. At this point, the concept of “Ensemble” comes out. Ensemble means using multiple learning algorithms to get better performance than using one algorithm. With Ensemble you can get better predictive power, but the downside is that it’s very computationally intensive. Representative Ensemble techniques are bagging and boosting
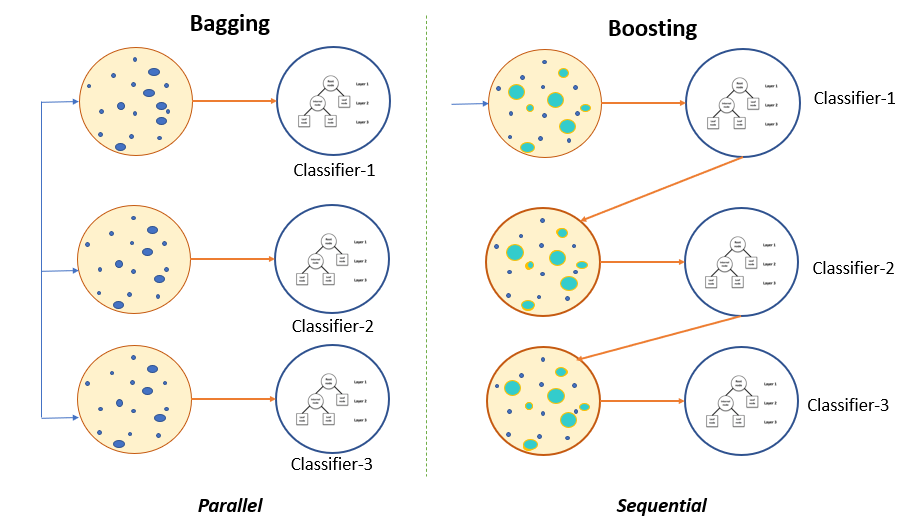
Bagging
Bootstrap is a language used in statistics and refers to random sampling. Bagging prevents overfitting or underfitting by accumulating bootstrap, giving sufficient learning effect even if the training data is insufficient.
Boosting
Boosting is similar to bagging, but the difference is that it learns sequentially. Also, based on the previous training result, the sample weight is adjusted for the next training to proceed with training. It’s as if the previous learning influences the next one in a chain. As such, it can be a little more complicated than simply using bootstrap. Representative algorithms using boosting techniques are GradientBoost, AdaBoost, and XGBoost.
Gradient Boosting
One of the optimization methods for optimizing the loss function is Gradient Descent. Here, the loss function is differentiated to find the slope value and the point where the loss function is minimized. Gradient Boosting is also easy to understand if you think about it similarly. For example, when you create a decision tree and train it, the difference between the actual value and the predicted value is Pusedo Residual, and it is a method to gradually multiply the learning rate to get closer to the target value.
Adaboost
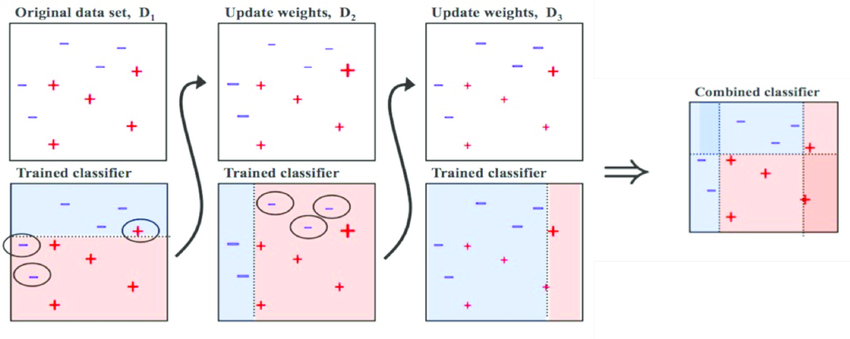
AdaBoost is also the most widely used algorithm among boosting methods. The difference from Gradient Boosting is that Gradient Boosting uses the Gradient Descent method to make the difference from the previous model smaller and smaller. AdaBoost uses a method of adjusting weights, not reducing errors with previous models. First, the information about the misclassified by the learned classifier is supplemented by the next classifier, which adaptively changes the weights of the samples misclassified by the previous classifier, allowing more focus on the misclassified data. So the name is AdaBoost. However, the downside is that it focuses only on parts that are difficult to classify.
XGBoost
XGBoost is short for Extreme Gradient Boosting. The advantage of XGBoost is that visualization is easier and more intuitive than neural networks. It also has better performance than Gradient Boosting, and it’s fast. The initial predicted value is set to an arbitrary value and the predicted value is divided in a way that maximizes the gain. The difference between the before and after Similarity Score is set as Gain, and the Similarity Score is the value obtained by dividing Sum of Residuals by Number of Residuals. If the result is no longer improved, the learning ends, and the final result is selected by boosting with each weight of all decision trees created.
LightGBM
Lightgbm is better to use when the data size is small rather than when it is large. It is named light because it takes up less memory while dealing with large amounts of data. The detailed algorithm will be covered in detail next time.
